

L’essentiel en 5 points
- 1 ChatGPT obtient des scores de QI très élevés (155 chez Roivainen, 150 chez Luc Ferry) sur les sous-tests verbaux du WAIS, ce qui alimente la thèse d’une IA mille fois plus intelligente que nous.
- 2 Ces scores sont méthodologiquement invalides parce que les items du Wechsler et des autres tests de QI sont publiés depuis des décennies et présents dans les corpus d’entraînement des LLM, qui les ont mémorisés.
- 3 Aboutir à un score élevé sur un test dont le candidat a vu les questions et les réponses ne mesure plus l’intelligence, cela mesure la mémoire associative, ce qu’un protocole psychométrique standard interdit explicitement.
- 4 L’intelligence est un construit opérationnalisé depuis un siècle (Spearman, Cattell, Carroll, modèle CHC, rapport Neisser 1996 de l’APA), dont aucune des dimensions mesurables n’a d’équivalent réel chez un LLM.
- 5 Confondre la performance fonctionnelle d’un LLM sur des tâches symboliques avec une intelligence au sens psychométrique produit des décisions coûteuses en RH, en orientation, en médecine, en politique éducative.
Quand un philosophe à deux agrégations annonce devant 200 personnes à Auxerre, puis devant la Mission d’information parlementaire sur l’IA, que l’intelligence artificielle est mille fois plus intelligente et cultivée que lui, personne ne lui demande ce qu’il entend par intelligente. Quand un psychologue finlandais publie dans Scientific American que ChatGPT obtient un QI verbal de 155, surpassant 99,9% de la population, l’information fait le tour des médias en quelques jours. Sciencepost, Futura-Sciences, Tom’s Guide, NeozOne reprennent le score sans le questionner.
Le problème est que le mot intelligence n’est pas un mot libre. Il a un sens scientifique, un siècle de travaux psychométriques, des outils de mesure aussi rigoureux que ceux de la médecine. Et quand on l’applique à un LLM, on l’applique sans avoir vérifié qu’il s’applique. Cet article explique pourquoi les scores de QI obtenus par ChatGPT et GPT-4 ne mesurent pas une intelligence, et pourquoi cette confusion est plus coûteuse qu’elle n’en a l’air.
Le score de QI 155 de ChatGPT, une histoire qui tourne en boucle
L’étude finlandaise de Roivainen et son écho médiatique
En 2023, le psychologue clinicien finlandais Eka Roivainen publie dans Scientific American une tribune dans laquelle il raconte avoir administré la troisième édition du Wechsler Adult Intelligence Scale (WAIS-III) à ChatGPT. Cinq des six sous-tests verbaux ont été passés : vocabulaire, similitudes, information, arithmétique, compréhension. Le sixième, la mémoire des chiffres, n’avait aucun sens pour un système qui n’a pas de fenêtre temporelle.
Le résultat publié : un score de QI verbal de 155, ce qui place théoriquement ChatGPT au-dessus de 99,9% des 2 450 personnes qui composent l’échantillon de normalisation américain du WAIS-III. L’information est reprise en boucle dans la presse francophone. Tom’s Guide titre « L’intelligence artificielle explose les compteurs ». Futura-Sciences évoque un « candidat idéal ». Sciencepost conclut que ChatGPT « serait très, très intelligent » s’il était humain.
155
Score de QI verbal de ChatGPT selon Roivainen (Scientific American, 2023). Ce score correspond théoriquement au 1‰ supérieur de la population. Sa validité psychométrique est nulle.
Luc Ferry et son score de 150 sur GPT-4
Dans son livre « IA, grand remplacement ou complémentarité ? » paru aux Éditions de l’Observatoire en janvier 2025, le philosophe Luc Ferry rapporte une expérience similaire. Il raconte avoir fait passer à GPT-4 des items issus du Wechsler et de l’échelle métrique de Zazzo (une adaptation française du Binet-Simon), dont il cite textuellement deux. La première : « Le boulanger perd sur chaque petit pain, mais il se rattrape sur la quantité, qu’est-ce qui ne va pas dans cette phrase ? ». La seconde : « Le vieux monsieur aimait faire le tour de son jardin mais arrivé exactement à mi-chemin, il était tellement fatigué qu’il devait faire demi-tour, où est la bêtise ? ».
GPT-4 répond aux deux questions de manière techniquement correcte, en quelques secondes, et Ferry en conclut que la machine atteint un score de 150, soit le 1% supérieur de la population. Il en tire que le mot intelligence s’applique légitimement aux LLM, même s’il distingue par ailleurs dans son livre trois types d’IA (faible et étroite, AGI, IA forte) et reconnaît que la conscience reste une affaire humaine.
Ces deux expériences, l’une publiée en presse scientifique grand public, l’autre dans un essai philosophique à fort retentissement, contribuent à fixer dans l’imaginaire collectif l’idée qu’un LLM est non seulement intelligent, mais plus intelligent que la quasi-totalité des humains. C’est cette conclusion qu’il faut démonter, parce qu’elle repose sur une erreur méthodologique grave que ni Roivainen ni Ferry n’ont identifiée.
Pourquoi ces tests ne mesurent rien chez un LLM
Le principe de la contamination des données
Le concept de contamination des données est central dans l’évaluation des modèles de langage. Il désigne la situation dans laquelle un système est testé sur des données qu’il a déjà vues pendant son entraînement. Quand cela se produit, la performance mesurée ne reflète plus la capacité du système à généraliser ou à raisonner, elle reflète sa capacité à restituer ce qu’il a mémorisé.
Or les items des tests de QI standardisés présentent une caractéristique qui rend la contamination quasi certaine : ils sont publiés depuis des décennies. Le Wechsler existe depuis 1939, ses différentes éditions (WAIS-R, WAIS-III, WAIS-IV, WAIS-V) sont documentées dans la littérature scientifique. Les items, ou des items très proches, circulent dans les manuels de psychologie, les sites de préparation aux concours de psychologue, les forums étudiants, les thèses universitaires, les ouvrages de vulgarisation, les bases de données académiques en accès libre. Les questions de Ferry sur le boulanger ou le vieux monsieur figurent dans des manuels disponibles en ligne depuis longtemps.
ChatGPT a été entraîné sur l’essentiel de ce qui est public sur internet jusqu’à son cutoff de données. Il a donc, statistiquement, vu ces items et leurs réponses des dizaines voire des centaines de fois pendant son entraînement. Sa performance sur ces questions ne mesure pas son intelligence, elle mesure le degré de mémorisation associative entre l’énoncé et la réponse attendue.

Ce qu’un protocole psychométrique exige et que les LLM ne respectent pas
Un test de QI sérieux repose sur plusieurs conditions strictes que la psychométrie a mises au point au fil d’un siècle de pratique :
La procédure standardisée garantit que tous les candidats passent les mêmes items dans les mêmes conditions, avec les mêmes consignes et les mêmes temps.
Le contrôle de l’exposition préalable garantit que le candidat n’a pas vu les items avant la passation. Les items des Wechsler sont protégés par copyright, leur diffusion est restreinte aux professionnels habilités, et les psychologues sont formés à détecter les candidats qui auraient été préparés à ces items.
L’équivalence des conditions de passation garantit que les performances sont comparables d’un candidat à l’autre.
La standardisation de l’échantillon de référence permet de situer un score individuel par rapport à une population de référence rigoureusement définie.
Aucune de ces conditions n’est respectée quand on fait passer un test à un LLM. La procédure n’est pas standardisée (Ferry choisit deux items, Roivainen cinq sous-tests). L’exposition préalable n’est pas seulement non contrôlée, elle est garantie par la nature même de l’entraînement des modèles. Les conditions de passation n’ont pas d’équivalent (pas de temps imparti, pas de stress, pas de fatigue, pas d’observation du candidat par un examinateur). L’échantillon de référence concerne des humains, pas des systèmes statistiques.
💡 POINT CLÉ
Aboutir à un score de 155 ou de 150 dans ces conditions ne constitue pas une mesure psychométrique. C’est une démonstration de la mémoire associative du système sur des items qu’il a vus, présentée avec le vocabulaire d’une science qu’elle ne respecte pas.
Mémoire associative ne signifie pas intelligence
L’objection peut sembler technique, elle est en réalité fondamentale. La psychométrie a précisément été inventée pour distinguer la performance brute (savoir donner la bonne réponse) du construit qu’elle cherche à mesurer (la capacité cognitive sous-jacente). Un élève qui aurait eu accès au corrigé d’un examen une semaine à l’avance et qui obtiendrait 19/20 n’aurait pas mesuré ses compétences, il aurait mesuré sa mémoire. C’est exactement la situation des LLM face aux tests de QI standardisés.
Un test de QI mesure l’intelligence à condition que les items soient nouveaux pour le candidat. Sinon, il mesure autre chose. C’est ce que les psychométriciens appellent un effet d’apprentissage, et c’est précisément pour cela qu’il existe des versions alternatives des tests pour les passations répétées chez les mêmes individus. Avec un LLM, l’effet d’apprentissage n’est pas un biais marginal, c’est la totalité de ce qui est mesuré.
Qu’est-ce que l’intelligence en psychométrie
Un siècle de mesure, de Spearman à Carroll
L’intelligence est probablement le construit psychologique le mieux validé qui existe en psychologie scientifique. Charles Spearman publie en 1904 les premiers travaux sur la mesure de l’intelligence et identifie le facteur général g, qui rend compte de la corrélation positive entre toutes les capacités cognitives mesurées. Raymond Cattell et John Horn distinguent ensuite l’intelligence fluide (Gf) et l’intelligence cristallisée (Gc). John Carroll synthétise en 1993 plus de 460 études d’analyse factorielle dans son ouvrage « Human Cognitive Abilities », qui structure encore aujourd’hui les tests modernes.
En 1996, l’American Psychological Association mandate une équipe d’experts présidée par Ulric Neisser pour publier l’état de la science. Le rapport « Intelligence: Knowns and Unknowns », paru dans American Psychologist, définit l’intelligence comme la capacité d’un individu à comprendre des idées complexes, à s’adapter à son environnement, à apprendre par l’expérience, à raisonner et à surmonter des obstacles par la pensée. C’est la référence consensuelle.
Le modèle CHC et ses dimensions mesurables
Le modèle Cattell-Horn-Carroll (CHC) opérationnalise cette définition en facteurs hiérarchiques mesurables, qui structurent les tests modernes comme le WISC-V pour les enfants, le WAIS-IV pour les adultes, ou le Woodcock-Johnson WJ-IV : g pour le facteur général, Gf pour le raisonnement fluide, Gc pour les connaissances cristallisées, Gv pour le traitement visuel, Gsm pour la mémoire à court terme, Glr pour la mémoire à long terme, Gs pour la vitesse de traitement, Ga pour le traitement auditif, Gq pour les connaissances quantitatives, Grw pour la lecture et l’écriture.
Ces facteurs ne sont pas des spéculations théoriques. Ils sont mesurés par des tests standardisés avec des coefficients de fidélité test-retest autour de 0,90, ce qui est très élevé pour une mesure psychologique. Leur validité prédictive est documentée sur la performance scolaire, la performance professionnelle (méta-analyses de Schmidt et Hunter), la santé et l’espérance de vie (travaux d’Ian Deary sur la cohorte écossaise).
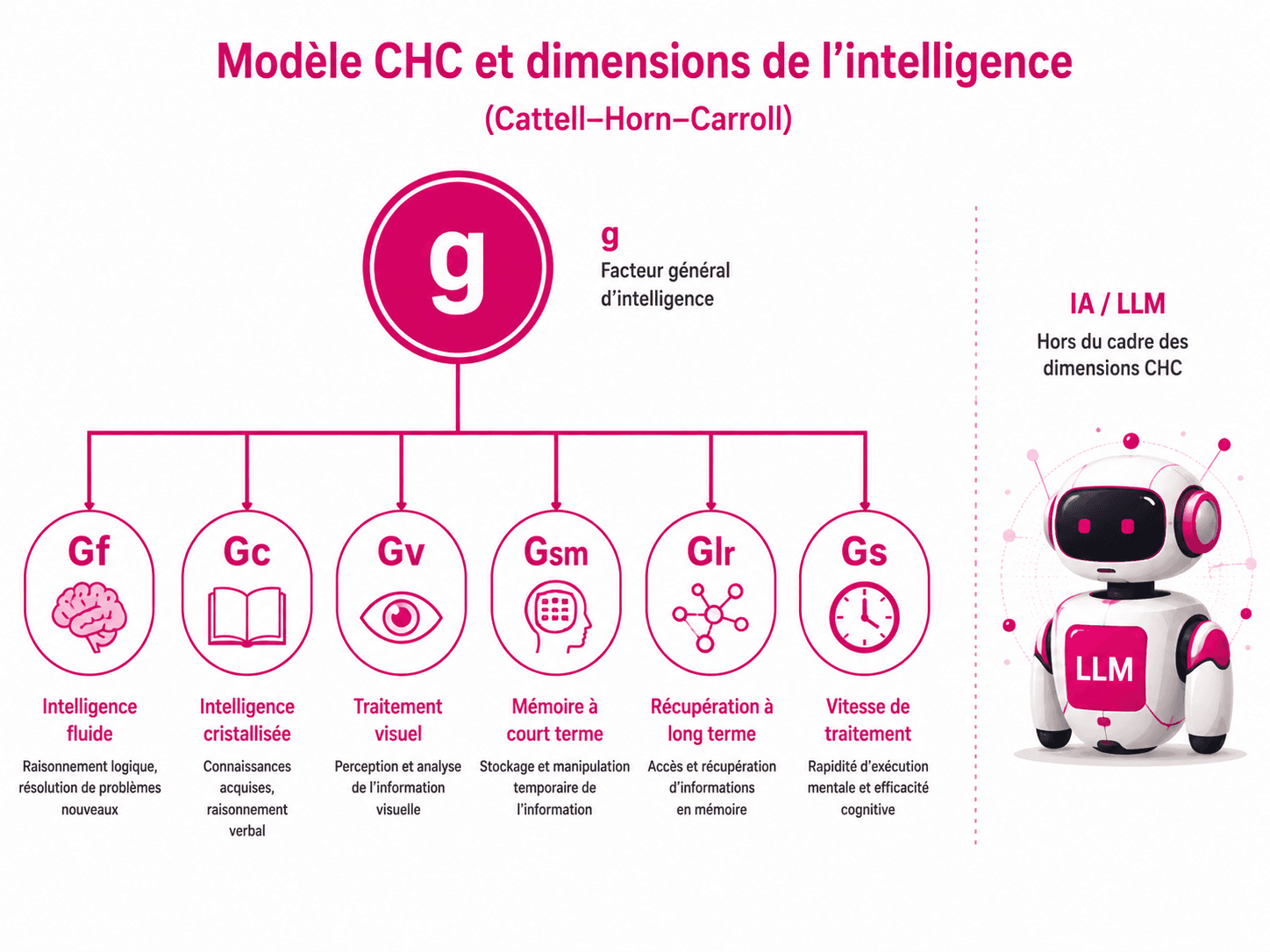
Pourquoi aucune dimension n’a d’équivalent chez un LLM
Aucun de ces facteurs n’a d’équivalent opérationnel chez un LLM. Pas un.
Le raisonnement fluide (Gf) implique de résoudre des problèmes nouveaux par induction et déduction. Les LLM échouent sur les benchmarks de généralisation compositionnelle hors distribution (Lake et Baroni 2018, Hupkes et al. 2020).
La mémoire de travail (Gsm) est la capacité à manipuler activement plusieurs éléments simultanément en mémoire. Les LLM n’ont pas de mémoire au sens psychologique, ils ont une fenêtre de contexte qui est lue à chaque inférence.
La vitesse de traitement (Gs) est la rapidité d’exécution de tâches cognitives simples chez un système doté d’attention, de fatigue, d’inhibition. Le débit d’inférence d’un GPU n’a aucun rapport avec ce construit.
Les connaissances cristallisées (Gc) sont l’accumulation de connaissances acquises par l’expérience dans une culture donnée. Un LLM stocke des distributions statistiques sur des tokens, pas des connaissances au sens d’un savoir intégré et mobilisable de manière flexible.
Quand on dit qu’un LLM a un QI, on utilise le vocabulaire d’une discipline scientifique sans en respecter aucune des conditions opérationnelles. C’est ce qu’on appelle un glissement lexical, et c’est précisément ce que la psychométrie sérieuse cherche à éviter.
Ce que fait vraiment ChatGPT
Le principe statistique sous le capot
Un LLM calcule la probabilité conditionnelle du prochain token étant donné les tokens précédents, à partir de poids appris par descente de gradient sur un corpus textuel massif. Mathématiquement, à chaque étape : produit matriciel sur des représentations vectorielles, fonction d’activation, softmax, échantillonnage du token suivant. Ce qui en sort est une suite de mots qui correspond à la continuation la plus probable du prompt selon la distribution apprise.
Pour le dire autrement : imaginez quelqu’un qui aurait passé sa vie enfermé dans une bibliothèque sans fenêtre, sans jamais voir un objet, toucher quoi que ce soit, parler à personne, mais qui aurait lu des milliards de phrases écrites par d’autres. Cette personne ne comprend pas vos questions au sens où vous les comprenez. Elle calcule quelle suite de mots a le plus de chances de venir après les vôtres, en piochant dans son stock de phrases déjà vues. C’est exactement ce que fait un LLM. Pas un déshonneur, mais autre chose qu’une intelligence.
Les limites documentées par les sciences cognitives
Trois courants de recherche convergent pour montrer que cette opération statistique n’est pas réductible à de l’intelligence.
La généralisation compositionnelle. Brenden Lake et Marco Baroni ont publié en 2018 un article dans les actes d’ICML montrant que les modèles séquence-à-séquence échouent dès qu’on leur demande de combiner des règles d’une façon qu’ils n’ont pas explicitement vue. McCoy et al. ont publié en 2023 « Embers of Autoregression », qui documente la sensibilité extrême des LLM à la fréquence des situations dans leurs données d’entraînement.
La distinction forme/sens. Emily Bender et Alexander Koller ont publié en 2020 dans les actes d’ACL « Climbing towards NLU », qui pose qu’un système entraîné uniquement sur la forme linguistique ne peut pas, en principe, apprendre le sens. Kyle Mahowald et son équipe ont publié en 2024 dans Trends in Cognitive Sciences un article cosigné avec Joshua Tenenbaum, Nancy Kanwisher et Evelina Fedorenko (l’élite des sciences cognitives au MIT) qui distingue compétence linguistique formelle (que les LLM maîtrisent bien) et compétence fonctionnelle (raisonnement, world model, modélisation de situations, cognition sociale), où les performances s’effondrent.
La causalité. Judea Pearl, lauréat du prix Turing, a posé une hiérarchie causale à trois niveaux : observer des corrélations, comprendre ce qui se passe quand on intervient, imaginer ce qui se serait passé sinon. Les LLM occupent le rez-de-chaussée.
Un enfant de trois ans fait quelque chose qu’aucun LLM ne fait
Posez une tasse au bord d’une table, poussez-la doucement. Un enfant de trois ans qui regarde anticipe : la tasse va tomber et se casser. Il le sait, pas parce qu’il a lu des milliards de phrases sur des tasses, mais parce qu’il a manipulé des objets, en a fait tomber, a vu ce qui se passe. Il a un modèle physique du monde dans la tête, construit par interaction sensorimotrice.
Elizabeth Spelke a documenté à Harvard que les bébés disposent dès quelques mois de connaissances de base sur les objets, l’espace, le nombre, les autres êtres vivants (les « core knowledge systems »). Susan Carey a montré comment les enfants construisent ensuite des concepts plus abstraits par bootstrapping conceptuel. Joshua Tenenbaum au MIT a modélisé mathématiquement la façon dont un enfant forme des hypothèses, les teste, les révise.

ChatGPT, à la même scène, produira la phrase « la tasse va se casser » parce que cette phrase est statistiquement dominante après une description similaire. Si dans son corpus la tasse s’envolait au plafond, il l’écrirait avec autant d’aplomb. Il n’a ni table ni gravité, il a des tokens et des distributions.
« L’IA générative a moins d’intelligence qu’un enfant de quatre ans, parce qu’elle est incapable d’avoir de la mémoire, incapable de planification et incapable de comprendre le monde. »
— Yann Le Cun, prix Turing 2018, directeur scientifique de Meta
Le glissement lexical et pourquoi il coûte cher
Le même mécanisme que MBTI, HP arborescent, synergologie
Le glissement lexical qui consiste à appliquer un mot scientifique à un objet qu’il ne décrit pas est un mécanisme connu dans le champ de la psychologie appliquée. Le « cerveau arborescent » qu’on prête aux enfants surdoués n’a aucune validation en neurosciences. Le MBTI rapporte des fortunes à ses ayants droit et n’a pas de fiabilité psychométrique sérieuse depuis qu’on prend la peine de le tester. La synergologie prétend lire la pensée sur le visage et appartient au registre du paranormal habillé en science. Le DISC repose sur les théories d’un auteur dont l’autre titre de gloire fut de créer Wonder Woman.
Le mécanisme est toujours le même : un mot scientifique, un test qui en a l’air, une apparence de mesure, et au bout du compte des décisions prises à partir d’illusions soigneusement entretenues. « L’IA est intelligente » fonctionne exactement pareil. La nouveauté n’est pas le mécanisme, c’est l’échelle. Les entreprises qui vendent cette confusion pèsent des milliards et les relais médiatiques n’ont aucun intérêt à les contrarier.

Les conséquences en RH, orientation, éducation, médecine
On déploie aujourd’hui ces systèmes dans des contextes à fort enjeu en présupposant qu’ils sont intelligents. Tri de CV en ressources humaines. Préconisation d’orientation pour des adolescents en bilan d’orientation. Aide à la décision médicale. Génération automatisée de bilans psychologiques. Politique publique sur l’éducation.
Dans chacun de ces cas, le mot intelligent fait silencieusement son travail. Il rassure le décideur. Il suggère un système qui comprend ce qu’il fait. Mais le système ne comprend pas, il calcule la phrase la plus probable étant donné ce qu’on lui a demandé. Et quand il se trompe sur un adolescent, sur un patient, sur un candidat, l’erreur n’est pas un accident rare. C’est l’expression normale d’un système qui n’a jamais été conçu pour faire ce qu’on lui demande, mais qui en donne l’illusion parce qu’on a accepté de l’appeler intelligent.
Reconnaître ce que les LLM font réellement
Les gains de productivité documentés
Refuser le mot intelligence n’est pas refuser l’utilité. Les LLM transforment réellement certaines pratiques professionnelles, et le nier serait aussi malhonnête que de les surévaluer.
Ils accélèrent la synthèse documentaire sur des corpus bien cadrés. Ils accélèrent la traduction de surface pour des textes standards. Ils accélèrent la programmation répétitive, et Peng et al. ont mesuré en 2023, dans une étude contrôlée sur GitHub Copilot, des gains de productivité réels chez les développeurs. Ils accélèrent la rédaction administrative et la production de premiers jets. Ils accélèrent la recherche d’information textuelle dans des bases volumineuses, via les architectures RAG (retrieval-augmented generation).
Un outil n’est pas un substitut
Mais accélérer une tâche n’est pas la même chose que la comprendre. Une calculatrice fait l’addition plus vite que vous, personne ne la qualifie de mathématicienne. Un médecin qui utilise un LLM pour rédiger un compte-rendu reste celui qui pose le diagnostic, parce qu’il a un patient devant lui qu’il a touché, écouté, examiné, dont il connaît l’histoire. Un psychologue qui utilise un outil numérique d’aide à la rédaction reste celui qui valide l’analyse clinique. Un conseiller en orientation qui utilise un test psychométrique numérique reste celui qui interprète les résultats à la lumière du dossier du jeune et de son projet.
La distinction est majeure, et elle structure la manière dont Eudonia et Espaces-Orientation conçoivent leurs outils. Les tests T-Persona, HEXA 3D, IRMR4 et WorkSens Pro sont des instruments psychométriques au sens fort, avec des construits opérationnalisés, des coefficients de fidélité publiés et des validations sur population. Ce qui les distingue d’un LLM auquel on demanderait de « faire un bilan » : ils mesurent quelque chose, ils n’inventent pas. Et leur lecture revient toujours au professionnel.

Conclusion
L’IA n’est pas intelligente. Pas au sens où le mot a un sens, c’est-à-dire celui défini par la seule discipline qui a opérationnalisé ce construit depuis un siècle. Les scores de 150 ou 155 obtenus par GPT-4 ou ChatGPT sur des items du WAIS ne mesurent pas l’intelligence du système, ils mesurent sa mémoire associative sur des items qu’il a vus pendant son entraînement. C’est une faute méthodologique, pas un résultat scientifique.
Les LLM sont utiles, parfois précieux, et tout à fait dépourvus d’intelligence au sens psychométrique. Reconnaître cela n’enlève rien à leur utilité, mais cela change ce qu’on attend d’eux et ce qu’on accepte de leur confier. Tant qu’on appellera intelligence ce qui est calcul probabiliste, on prendra des décisions sur des projections, pas sur des mesures. Et c’est précisément ce que la psychométrie sérieuse cherche à empêcher depuis cent ans.
Questions fréquentes
Des outils psychométriques validés pour vos évaluations
Eudonia conçoit des outils pour les professionnels de la psychologie et de l’orientation, qui mesurent des construits opérationnalisés, avec des coefficients de fidélité publiés. À la différence d’un LLM, ils mesurent quelque chose et leur lecture revient toujours au professionnel.